分布式系统中生成唯一ID
使用redis生成id
在分布式系统中,还可能使用流水号来追踪某一请求,以满足多个节点的协作。在这种情况下,并不需要插入数据,采用数据库机制就有点不合适了。为此,我们可以考虑使用Redis来满足这个要求。从性能上来说,Redis的性能要比数据库好得多。从扩展性来说,使用多个Redis服务器就能实现扩展。因此,无论是性能,还是可扩展性,Redis都要比数据库好很多。并且Redis可以在不插入数据的时候生成ID,为分布式协作提供流水号。
1、Spring boot实例代码如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<scope>provided</scope>
</dependency>
<!-- 加入Spring Boot的Redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
这样就能够引入Redis和Web相关的依赖包了。接着就需要在application.yml中配置对应的内容了。
# 配置启动端口
server:
port: 1013
# 配置Redis
spring:
redis:
# 服务器
host: 192.168.224.131
# 密码
password: 123456
# jedis配置
jedis:
#连接池配置
pool:
# 最大活动线程数
max-active: 20
# 最大空闲线程数
max-idle: 10
# 最小空闲线程数
min-idle: 5
# 最大等待1 s
max-wait: 1s
这样就配置好了启动的端口和关于Redis的配置,然后我们在Redis服务器上执行以下脚本。
hset user_table_key offset 1 -- ID开始值
hset user_table_key step 5 -- 步长
hset user_table_key current 1 -- 当前值
hset user_table_key start 0 -- 是否已经启用,0为不启用,1为启用
hgetall user_table_key -- 查看键(“user_table_key”)的所有信息
假设这里设置的是用户表ID的生成规则,这些规则使用Redis的哈希结构(Hash)进行保存。其中,开始值(offset)设置为1,步长(step)为5,这意味着下一个ID为1+5=6。启动标志(start)设置为0,表示没有开启,开启后设置为1。有了这些规则数据,我们就可以采用下列代码来获取对应的ID了。
package com.spring.cloud.chapter13.main;
/**** imports ****/
@SpringBootApplication
@RestController // REST风格控制器
@RequestMapping("/chapter13")
public class Chapter13Application {
public static void main(String[] args) {
SpringApplication.run(Chapter13Application.class, args);
}
private String lua = // ①
// 获取是否启用标志
" local start = redis.call('hget', KEYS[1], 'start') \n"
// 如果未启用
+ " if tonumber(start) == 0 then \n"
// 获取开始值
+ " local result = redis.call('hget', KEYS[1], 'offset') \n"
// 将当前值设置为开始值
+ " redis.call('hset', KEYS[1], 'current', result) \n"
// 将是否启用标志设置为已经启用(1)
+ " redis.call('hset', KEYS[1], 'start', '1') \n"
// 返回结束
+ " return result \n"
// 结束if语句
+ " end \n"
// 获取当前值
+ " local current = redis.call('hget', KEYS[1], 'current') \n"
// 获取步长
+ " local step = redis.call('hget', KEYS[1], 'step') \n"
// 结算新的当前值
+ " local result = current + step \n"
// 设置新的当前值
+ " redis.call('hset', KEYS[1], 'current', result) \n"
// 返回结果
+ " return result \n";
@Autowired
private StringRedisTemplate stringRedisTemplate = null;
/**
* 获取对应的ID
* @param keyType -- Redis的键
* @return ID
*/
@GetMapping("/id/{keyType}")
public String getKey(@PathVariable("keyType") String keyType) { // ②
// 结果返回为Long
DefaultRedisScript<Long> rs = new DefaultRedisScript<Long>();
rs.setScriptText(lua);
rs.setResultType(Long.class);
// 定义脚本中的key参数
List<String> keyList = new ArrayList<>();
keyList.add(keyType);
// 执行脚本,并传递参数
Object result = stringRedisTemplate.execute(rs, keyList);
return result.toString();
}
}
这段代码比较长,核心是代码①处的Lua脚本。在代码中,我做了详细的注释,请自行参考。代码②处的getKey方法是执行Lua脚本的。有了这段代码,启动模块chapter13,然后在浏览器中打开网址http://localhost:1013/chapter13/id/user_table_key,就能看到返回的一个ID。这里因为Redis执行Lua脚本的过程是具备原子性的,所以不会产生重号的问题。在ID规则中设置了步长为5,也就是可以启用5个Redis服务器节点来生成ID,这足以满足一般应用性能的需要了。如果有必要,可以把步长设置得更大一些,这样就可以使用更多的Redis服务器节点来提高性能了。
使用Redis的方式,比数据库的方式快速。但是因为Redis服务可能出现故障,所以一般会考虑使用哨兵和集群等方式来降低故障的发生,从而保证系统能够持续提供服务。但是这样会依赖Redis服务,且算法也比较复杂,这会增加开发者实现的复杂度,造成性能的下降。
时钟算法
在时间表达上,Java的java.util.Date类使用了长整型数字进行表示,该数字代表距离格林尼治时间1970年1月1日整点的毫秒数。因此很多开发者提出利用这点,采用时钟算法来获取唯一的ID。使用时钟算法的好处有这么几点。
- 相对简单,可以获取一个整数型,有利于数据库的性能。
- 可以知道业务发生的时间点,通过时间来追踪业务。
- 如果在原有时间信息的基础上加入数据存储机器编号,就能快速定位业务。
在介绍时钟算法前,我们需要对Java中的时间有一定的认知,为此,这里先介绍一些简单的知识。在Java的System类中有下列两个静态(static)方法。
// 返回当前时间,精确到毫秒
System.currentTimeMillis();
// 返回当前时间,精确到纳秒
System.nanoTime();
这便是获取当前时间长整型数字的方法,此外还需要大家记住的下面的单位换算规则:
1s=1000ms
1ms=1000μs=1000000ns
从上述的单位换算来看,毫秒(ms)已经是一个很小的单位,纳秒(ns)则是一个更加小的时间单位,这就意味着,使用它则需要更多位数的长整型数字表示。而事实上,一些数据库能够允许的整数位是有限的。拿MySQL来说,BIGINT(大整数)类型支持的数字的大小范围是64位二进制,有符号的范围是−263 ~263−1;而INT类型(整数)支持的数字范围是32位二进制,有符号的范围是−231~231−1。一个纳秒时间的数值在BIGINT类型的范围之内,在INT类型的范围之外。因此当前纳秒时间的长整型数字完全可以作为一个主键,于是就可以在Chapter13Application中添加下列代码,用来生成主键。
// 同步锁
private static final Class<Chapter13Application> LOCK
= Chapter13Application.class;
public static long timeKey() {
// 线程同步锁,防止多线程错误
synchronized (LOCK) { // ①
// 获取当前时间的纳秒值
long result = System.nanoTime();
// 死循环
while(true) {
long current = System.nanoTime();
// 超过1 ns后才返回,这样便可保证当前时间肯定和返回的不同,
// 从而达到排重的效果
if (current - result > 1) { // ②
// 返回结果
return result;
}
}
}
}
先看一下代码①处,这里启用了同步锁机制,保证在多线程中不会出现差错,并且在同步代码块中获取了当前时间的纳秒值。为防止调用产生同样的时间纳秒值,代码②处退出死循环,让程序循环到下一个纳秒才返回,这样就能够保证其返回ID的唯一性了。
从上述代码可以看到,使用时钟算法相对来说比较简单。实际测试时,使用上列代码可以每秒产生数百万个ID,显然在性能上是十分优越的,甚至只需要使用单机就能够满足分布式系统发号的需求。但是如果在多个分布式节点上使用这样简易的时钟算法,就有可能发出重复的号,所以这种简单的时钟算法并不能应用在多个分布式节点上。另外,有些企业希望ID能够放入更多的业务逻辑,以便在后续出现问题时定位具体出现问题的机器和数据库,于是就出现了一些变种的时钟发号算法,其中最出名、使用最广泛的当属SnowFlake算法。
变异时钟算法——SnowFlake算法(推荐)
SnowFlake(雪花)算法是Twitter提出的一种算法,我们之前在阐述时钟算法的时候谈到过,如果MySQL的主键采用BIGINT(大整数)类型,那么它的取值范围是−263到263−1,从计算机原理的角度来说,存储一个BIGINT类型就需要64位二进制位。基于这个事实,SnowFlake算法对这64位二进制位做了下图所示的约定。
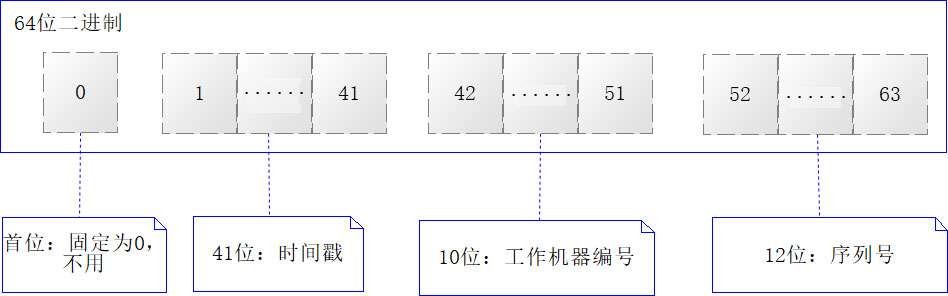
关于SnowFlake算法对于64位二进制的约定,这里结合上图做更为详细的阐述。
- 第1位二进制值固定为0,没有业务含义,在计算机原理中,它是一个符号位,0代表正数,1代表负数,这里恒定为0。
- 第2~42位,共41位二进制,为时间戳位,用于存入精确到毫秒数的时间。
- 第43~52位,共10位二进制,为工作机器id位,其中工作机器又分为5位数据中心编号和5位受理机器编号,而5位二进制表达整数时取值区间为[0, 31]。
- 第53~64位,共12位二进制,代表1ms内可以产生的序列号,当它表示整数时,取值区间为[0, 4095]
第1位二进制值固定为0,没有业务含义,在计算机原理中,它是一个符号位,0代表正数,1代表负数,这里恒定为0。●第2~42位,共41位二进制,为时间戳位,用于存入精确到毫秒数的时间。●第43~52位,共10位二进制,为工作机器id位,其中工作机器又分为5位数据中心编号和5位受理机器编号,而5位二进制表达整数时取值区间为[0, 31]。●第53~64位,共12位二进制,代表1ms内可以产生的序列号,当它表示整数时,取值区间为[0, 4095]
package com.spring.cloud.chapter13.main;
public class SnowFlakeWorker {
// 开始时间(这里使用2019年4月1日整点)
private final static long START_TIME = 1554048000000L;
// 数据中心编号所占位数
private final static long DATA_CENTER_BITS = 10L;
// 最大数据中心编号
private final static long MAX_DATA_CENTER_ID = 1023;
// 序列编号占位位数
private final static long SEQUENCE_BIT = 12L;
// 数据中心编号向左移12位
private final static long DATA_CENTER_SHIFT = SEQUENCE_BIT ;
/** 时间戳向左移22位(10+12) */
private final static long TIMESTAMP_SHIFT
= DATA_CENTER_BITS + DATA_CENTER_SHIFT;
// 最大生成序列号,这里为4095
private final static long MAX_SEQUENCE = 4095;
// 数据中心ID(0~1023)
private long dataCenterId;
// 毫秒内序列(0~4095)
private long sequence = 0L;
// 上次生成ID的时间戳
private long lastTimestamp = -1L;
/**
* 因为当前微服务和分布式趋向于去中心化,所以不存在受理机器编号,
* 10位二进制全部用于数据中心
* @param dataCenterId -- 数据中心ID [0~1023]
*/
public SnowFlakeWorker(long dataCenterId) { // ①
// 验证数据中心编号的合法性
if (dataCenterId > MAX_DATA_CENTER_ID) {
String msg = "数据中心编号[" + dataCenterId
+"]超过最大允许值【" + MAX_DATA_CENTER_ID + "】";
throw new RuntimeException(msg);
}
if (dataCenterId < 0) {
String msg = "数据中心编号[" + dataCenterId + "]不允许小于0";
throw new RuntimeException(msg);
}
this.dataCenterId = dataCenterId;
}
/**
* 获得下一个ID (为了避免多线程环境产生的错误,这里方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
// 获取当前时间
long timestamp = System.currentTimeMillis();
// 如果是同一个毫秒时间戳的处理
if (timestamp == lastTimestamp) {
sequence += 1; // 序号+1
// 是否超过允许的最大序列
if (sequence > MAX_SEQUENCE) {
sequence = 0;
// 等待到下一毫秒
timestamp = tilNextMillis(timestamp); // ②
}
} else {
// 修改时间戳
lastTimestamp = timestamp;
// 序号重新开始
sequence = 0;
}
// 二进制的位运算,其中“<<”代表二进制左移,“|”代表或运算
long result = ((timestamp - START_TIME) << TIMESTAMP_SHIFT)
| (this.dataCenterId << DATA_CENTER_SHIFT)
| sequence; // ③
return result;
}
/**
* 阻塞到下一毫秒,直到获得新的时间戳
* @param lastTimestamp -- 上次生成ID的时间戳
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp;
do {
timestamp = System.currentTimeMillis();
} while(timestamp > lastTimestamp);
return timestamp;
}
}
这个算法的难点在于二进制的位运算。代码①处的构造方法,主要是验证和绑定数据中心编号(dataCenterId)。核心是nextId方法,它通过获取当前时间毫秒数,判断上次生成的ID是否在同一个时间戳内,于是,计算序号就存在两种可能。第一种可能是在同一个时间戳内,这个时候通过序号加一的方法来处理。而代码②处的序号已经超过最大限制,这时候通过tilNextMillis方法阻塞到下一毫秒,就可以获得下一毫秒的时间戳,避免产生重复的ID。第二种可能是不在同一个时间戳内,这个时候让序号从0重新开始,且重新记录上次生成ID的时间戳即可。接下来看代码③处,这里的运算为二进制位运算,其中,通过左移运算符“<<”将对应的二进制数字移动到对应的位上,然后通过“|”将数字拼凑在一起,最终生成ID。通过循环测试nextId方法可以看到生成的ID,代码如下:
4151043847884800
4151043847884801
4151043847884802
4151043847884803
4151043847884804
4151043847884805
4151043847884806
4151043847884807
4151043847884808
4151043847884809
4151043847884810
4151043847884811
4151043847884812
4151043847884813
......
由以上ID可见,存在16位数字,按照给出的算法保证了ID的唯一性。SnowFlake算法是一种高效的算法,每秒可以产生数十万的ID,它包含了数据中心(旧算法在不去中心化的情况下还可以包含受理机器编号)、时间戳和序号3种业务逻辑,可以在一定的程度上帮助我们定位业务。由于性能好且带有一定的业务数据,因此受到了许多互联网企业的青睐,使用得也比较广泛。
自定义发号机制
在前面介绍SnowFlake算法的时候,我谈到了它的诸多缺点,例如,产生的序号和机器位可能浪费了太多的二进制。为了克服这些问题,我们会改造SnowFlake算法,编写自定义发号机制。
在改造前,需要先明确自己的系统的实际情况,这是第一步。这里做如下假设:
- 在改造前,需要先明确自己的系统的实际情况,这是第一步。这里做如下假设
- 系统不会超过每秒10万次的请求(这符合大部分企业的需求),如果超过可以使用限流算法进行处理,所以序号使用8位二进制即可,这样原来的12位就能够节省出4位了
由此来看,一共可以节省6位二进制,可以用于表示发号机器编号,这样就可以同时在多个节点上使用发号算法了。但是需要进行约定,为了更好地讲述约定,先看一下图
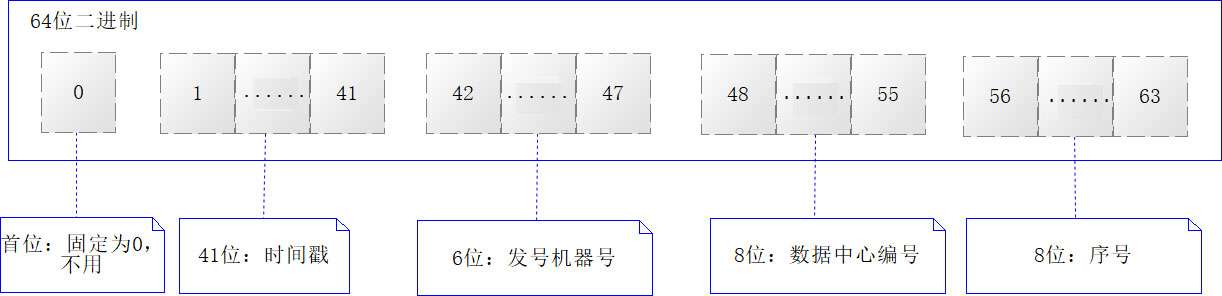
在上图中,约定如下。
- 第1位二进制固定为0
- 第2~42位,共41位二进制,存储时间戳
- 第43~48位,共6位二进制,存储发号机器号
- 第49~56位,共8位二进制,存储数据中心编号
- 第57~64位,共8位二进制,存储序号
有了这些约定,就可以实现算法了
package com.spring.cloud.chapter13.main;
public class CustomWorker {
// 开始时间(这里使用2019年4月1日整点)
private final static long START_TIME = 1554048000000L;
// 当前发号节点编号(最大值63)
private static long MACHINE_ID = 21L;
// 最大数据中心编号
private final static long MAX_DATA_CENTER_ID = 127L;
// 最大序列号
private final static long MAX_SEQUENCE = 255L;
// 数据中心位数
private final static long DATA_CENTER_BIT=8L;
// 机器中心位数
private final static long MACHINE_BIT= 6L;
// 序列编号占位位数
private final static long SEQUENCE_BIT = 8L;
// 数据中心移位(8位)
private final static long DATA_CENTER_SHIFT = SEQUENCE_BIT;
// 当前发号节点移位(8+8=16位)
private final static long MACHINE_SHIFT
= SEQUENCE_BIT + DATA_CENTER_BIT;
// 时间戳移位(8+8+6=22位)
private final static long TIMESTAMP_SHIFT
= SEQUENCE_BIT + DATA_CENTER_BIT + MACHINE_BIT;
// 数据中心编号
private long dataCenterId;
// 序号
private long sequence = 0;
// 上次时间戳
private long lastTimestamp;
public CustomWorker(long dataCenterId) {
// 验证数据中心编号的合法性
if (dataCenterId > MAX_DATA_CENTER_ID) {
String msg = "数据中心编号[" + dataCenterId
+ "]超过最大允许值【" + MAX_DATA_CENTER_ID + "】";
throw new RuntimeException(msg);
}
if (dataCenterId < 0) {
String msg = "数据中心编号[" + dataCenterId + "]不允许小于0";
throw new RuntimeException(msg);
}
this.dataCenterId = dataCenterId;
}
/**
* 获得下一个ID (该方法是线程安全的)
* @return 下一个ID
*/
public synchronized long nextId() {
// 获取当前时间
long timestamp = System.currentTimeMillis();
// 如果是同一个毫秒时间戳的处理
if (timestamp == lastTimestamp) {
sequence += 1; // 序号+1
// 是否超过允许的最大序列
if (sequence > MAX_SEQUENCE) {
sequence = 0;
// 等待到下一毫秒
timestamp = tilNextMillis(timestamp);
}
} else {
// 修改时间戳
lastTimestamp = timestamp;
// 序号重新开始
sequence = 0;
}
// 二进制的位运算,其中“<<”代表二进制左移,“|”代表或运算
long result = ((timestamp-START_TIME) << TIMESTAMP_SHIFT)
| (MACHINE_ID << MACHINE_SHIFT)
| (this.dataCenterId << DATA_CENTER_SHIFT)
| sequence;
return result;
}
/**
* 阻塞到下一毫秒,直到获得新的时间戳
* @param lastTimestamp -- 上次生成ID的时间戳
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp;
do {
timestamp = System.currentTimeMillis();
} while(timestamp > lastTimestamp);
return timestamp;
}
}
这个算法和SnowFlake算法大同小异,只是二进制位表达的含义略微有所不同。代码中,我已经给出了注释,请读者自行参考。这个自定义的算法也加入了发号节点编号,能够支持区间[0, 63]的64个数字的编号,这样该算法就能够支持最多64个发号节点的服务了
通过自定义算法,我只是想告诉大家,发号机制没有固定不变的方法,只要合理即可。但是ID会受到数据存储的限制,例如,MySQL的BIGINT类型也只能支持−263到263−1的范围,这是需要注意的地方。如果需要MySQL支持更多的位数,可以使用DECIMAL类型,但DECIMAL是一种格式化的数字,如金额,其内部算法比较复杂,性能上不如BIGINT高,所以在大部分情况下,我都推荐使用BIGINT作为主键
总结
前面我们讨论了几种常见的发号机制,并且讨论了它们的利弊。在现实中,可以根据自己的需要进行选型。此外,还有使用ZooKeeper分布式锁或者MongoDB的ObjectId机制来生成分布式ID的办法,只是它们比较复杂,并且性能不高,所以这里就不介绍了。实际上,我们也不需要受限于这些所谓的常见办法,因为我们也可以自定义发号算法。
记录笔记并调整 << Spring Cloud微服务和分布式系统实践 >> 作者: 杨开振

