分布式数据库
对分布式和微服务来说,一种业务就可能有很多的数据,如交易,单数据库也很有可能无法支撑,需要多个数据库节点进行支持,这种需要将数据库拆分为多节点进行存储的技术,便是本章需要讨论的分布式数据库技术。
数据库的分表、分库和分区的概念
分表是指在一个或者多个数据库实例内,将一张表拆分为多张表存储,本文只讨论同一个数据库拆分,但多个数据库拆分实际也是大同小异的。一般来说,分表是因为该表需要存储很庞大的记录数,如果将其堆积到一起,就会导致数据量过于庞大(一般MySQL的表是5000万条记录左右)引发性能瓶颈。一般分表会按照某种算法进行拆分,如交易记录,可能按年份拆分,如下图所示。
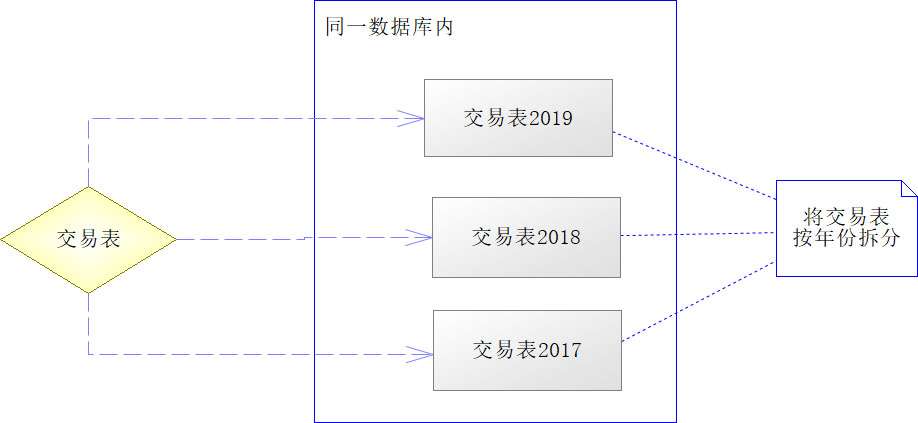
从上图中可以看到,将同一个数据库中的交易表按年份进行拆分,可以使交易记录不再只保存在一个表中,从而避免单表数据记录过多的问题。但是这样的分法也会导致一些问题,就是一张表不再存在全部完整的数据,进行总体查询的时候,需要分表查找,在做统计和分析时,需要跨表查询,这时需要引入路由算法和合并算法等才能得到所需的数据。
分库是指将一套数据库的设计结构,部署到多个数据库实例的节点中去,在应用的时候,按照一定的方法通过多个数据库实例节点访问数据。请注意,这里的数据库实例节点是一个逻辑概念,不是一个物理概念,什么意思呢?简单地说,一个机器节点可以部署多个数据库实例节点,也可以一个机器节点只部署一个数据库实例节点,所以机器节点不一定等于数据库节点。而机器节点是物理概念,是看得到的真实的机器;数据库节点是逻辑概念,是看不到的东西。为了更好地说明分库的概念,我们看下图。
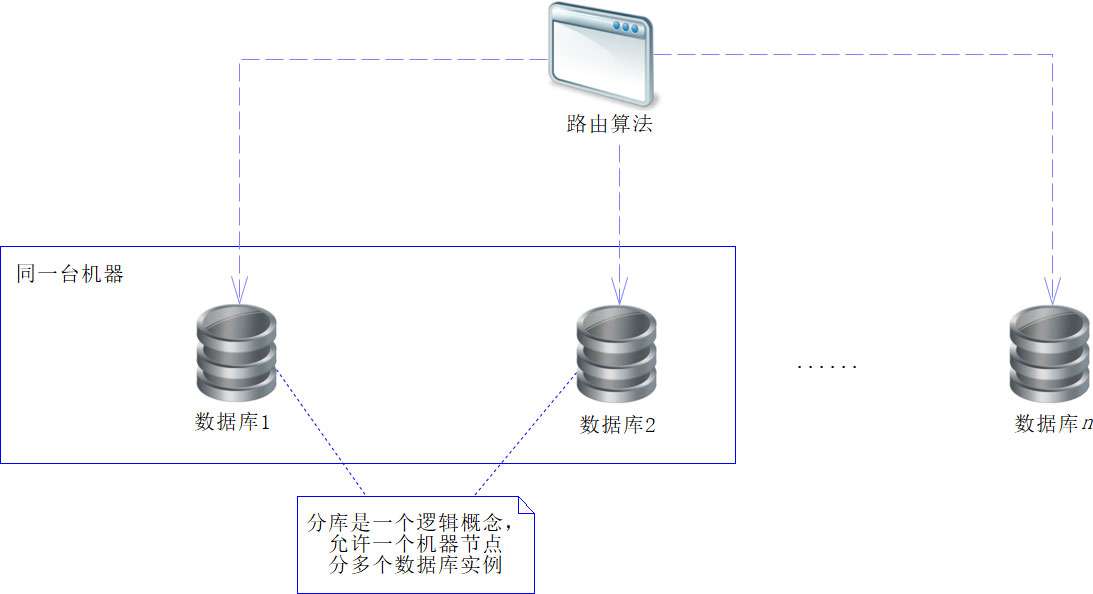
因为将数据库分为多个节点,所以需要一个路由算法来确定数据具体存放在哪个库中,于是路由算法就成了我们关注的核心内容之一。最简单的路由算法是求余算法。例如,现在划分为3个数据库,在获取用户ID(userId,假设是一个Long型数据)后,采用userId对3求余(userId%3),得到余数(可能为0或1或2),然后再根据余数存放到对应的库中。当然,这样也会有一定的缺点,为此有人提出了一致性哈希算法,这些我们会在后续进行讨论。
分区是指一张表的数据分成n个区块,在逻辑上看,最终只是一张表,但底层是由n个物理区块组成的,如下图所示。
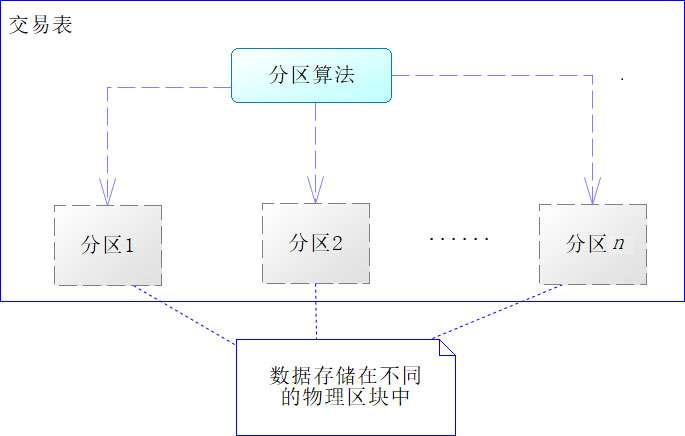
分区技术与分表技术很类似,只是分区技术属于数据库内部的技术,对于开发者来说,它逻辑上仍旧是一张表,开发时不需要改变SQL表名。将一张表切分为多个物理区块,有以下这么几个好处。
- 相对于单个文件系统或是磁盘,分区可以在不同的磁盘上存储更多的数据
- 相对于单个文件系统或是磁盘,分区可以在不同的磁盘上存储更多的数据
- 相对于单个文件系统或是磁盘,分区可以在不同的磁盘上存储更多的数据
- 支持CPU多线程同时查询多个分区磁盘,提高查询的吞吐量
- 在涉及聚合函数查询时,可以很容易地合并数据
不过,从当前来说,分表技术已经渐渐淡出了人们的选择。因为分表会导致表名变化,产生逻辑不一致,继而加大后续开发的工作量和统计上的困难。当前采用更多的是分库技术,分库技术的伸缩性更好,可以增加节点,也可以减少节点,比较灵活。但是由于分布在多个节点中,因此需要其他的技术将它们整合成为一个整体。分区则是数据库内部的技术,当前Oracle和MySQL 5.1后的版本都能够支持分区技术,只是分区并不是分布式技术,并非本节需要讨论的问题,所以需要进行分区的读者,可以参考相关数据库的资料
Spring多数据源支持
为了更好地进行论述,这里假设我们系统中有3个数据库,在这些数据库中有一张交易表,该表建表语句如下:
create table t_transaction (
id bigint not null comment '主键,采用SnowFlake算法生成',
user_id bigint not null comment '用户编号',
product_id bigint not null comment '商品编号',
payment_channel tinyint not null
comment '交易渠道,字典:1-银行卡交易,2-微信支付,3-支付宝支付,4-其他支付',
amout decimal(10, 2) not null comment '交易金额',
quantity int not null default 1 comment '交易商品数量',
discount decimal(10, 2) not null default 0 comment '优惠金额',
trans_date timestamp not null comment '交易日期',
note varchar(512) null comment '备注',
primary key (id)
);
在学习的过程中,在单机的情况下也可以创建3个数据库实例进行模拟,我也是如此,为此分别创建了3个库:sc_chapter14_1、sc_chapter14_2和sc_chapter14_3。
然后我们给3个库进行编号,如下图所示。

然后我们引入依赖包spring-boot-starter-jdbc,这样就能加载Spring关于JDBC的类库进来了。当中有一个抽象类AbstractRoutingDataSource,英文的翻译是抽象路由数据源。为了更好地使用它,我们进行一定的源码分析,如代码下午图所示。
package org.springframework.jdbc.datasource.lookup;
/**** imports ****/
public abstract class AbstractRoutingDataSource
extends AbstractDataSource implements InitializingBean { // ①
// 目标数据源,Map类型,可支持多个数据源,通过Key决定
@Nullable
private Map<Object, Object> targetDataSources;
// 默认数据源
@Nullable
private Object defaultTargetDataSource;
// 是否支持降级
private boolean lenientFallback = true;
// 通过JNDI查找数据源
private DataSourceLookup dataSourceLookup = new JndiDataSourceLookup();
// 通过解析后的数据源(包含原始数据源和JNDI数据源)
@Nullable
private Map<Object, DataSource> resolvedDataSources;
// 默认解析后的数据源
@Nullable
private DataSource resolvedDefaultDataSource;
.......
// Spring属性初始化后调用方法
@Override
public void afterPropertiesSet() {
// 没有目标数据源设置
if (this.targetDataSources == null) {
throw new IllegalArgumentException(
"Property 'targetDataSources' is required");
}
// 解析数据源存放到resolvedDataSources 中
this.resolvedDataSources
= new HashMap<>(this.targetDataSources.size());
this.targetDataSources.forEach((key, value) -> { // ②
Object lookupKey = resolveSpecifiedLookupKey(key);
DataSource dataSource = resolveSpecifiedDataSource(value);
this.resolvedDataSources.put(lookupKey, dataSource);
});
// 如果默认的数据源为空,则进行设置
if (this.defaultTargetDataSource != null) {
this.resolvedDefaultDataSource
= resolveSpecifiedDataSource(this.defaultTargetDataSource);
}
}
// 选择具体的数据源
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources,
"DataSource router not initialized");
// 获取数据库的key
Object lookupKey = determineCurrentLookupKey(); // ③
// 尝试通过key得到的数据源
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
// 如果为空则使用默认
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException(
"Cannot determine target DataSource for lookup key ["
+ lookupKey + "]");
}
return dataSource;
}
// 获取key的抽象方法
@Nullable
protected abstract Object determineCurrentLookupKey(); // ④
}
代码①处实现了InitializingBean接口,这就意味着IoC容器装配为Spring Bean的时候,就会调用afterPropertiesSet方法。在afterPropertiesSet方法中,它解析了目标数据源(targetDataSources,它是一个Map结构,通过key进行访问),这里的目标数据源是提供给开发者配置的,配置的方式可能是原始的JDBC配置方式,也可能是JNDI的配置方式,所以需要进行解析,然后放入到解析后的数据源(resolvedDataSources)中,并且设置默认的数据源。再看determineTargetDataSource方法,它是一个选择具体数据源的方法,这里注意,解析后的数据源(resolvedDataSources)是一个Map结构,所以依赖key进行访问。代码③处是获取key的方法,这个方法依赖代码④定义的抽象方法determineCurrentLookupKey,通过这个key,可以到解析后的数据源(resolvedDataSources)中,找对应的数据库。这里的抽象方法determineCurrentLookupKey要由非抽象的子类来实现。
spring 代码整合
package com.spring.cloud.chapter14.pojo;
/**** imports ****/
@Alias("transaction") // 定义MyBatis别名
public class Transaction implements Serializable {
public static final long serialVersionUID = 2323902389475832678L;
private Long id;
private Long userId;
private Long productId;
private PaymentChannelEnum paymentChannel = null; // 枚举
private Date transDate;
private Double amout;
private Integer quantity;
private Double discount;
private String note;
/**** setters and getters ****/
}
这里需要解释的是@Alias(“transaction”),它的意思是定义一个MyBatis的别名,即可以用字符串“transaction”在MyBatis上下文中代替类Transaction。这里的定义中,还有一个枚举类型,在MyBatis中需要进行处理,具体如何处理我们后文再谈,这里先给出枚举的定义,如下图代码所示。
package com.spring.cloud.chapter14.enumeration;
public enum PaymentChannelEnum {
BANK_CARD(1, "银行卡交易"),
WE_CHAT(2, "银行卡交易"),
ALI_PAY(3, "支付宝"),
OTHERS(4, "其他方式");
private Integer id;
private String name;
PaymentChannelEnum(Integer id, String name) {
this.id = id;
this.name = name;
}
public static PaymentChannelEnum getById(Integer id) {
for (PaymentChannelEnum type : PaymentChannelEnum.values()) {
if (type.getId().equals(id)) {
return type;
}
}
throw new RuntimeException(
"没有找到对应的枚举,请检测id【" + id + "】");
}
/** setters and getters **/
}
跟着提供一个接口定义,如下图代码所示。
package com.spring.cloud.chapter14.dao;
/**** imports ****/
@Mapper // 标记为MyBatis的映射(Mapper)
public interface TransactionDao {
/**
* 根据用户编号(userId)查找交易
* @param userId -- 用户编号
* @return 交易信息
*/
public List<Transaction> findTranctions(Long userId);
}
注意,这里只需要接口定义而无须实现类,具体的类由MyBatis内部机制实现。这里的@Mapper的含义是标记这个接口为MyBatis的一个映射器。跟着要对这个接口捆绑SQL,创建MyBatis的映射文件——transaction_mapper.xml,然后将其放在模块文件夹/resources/mybatis下,其内容如下图代码所示。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.spring.cloud.chapter14.dao.TransactionDao"> <!--①-->
<select id="findTranctions" resultType = "transaction"> <!--②-->
SELECT id, user_id as userId, product_id as productId,
trans_date as transDate, payment_channel as paymentChannel,
amout, quantity, discount, note
FROM t_transaction where user_id = #{userId}
</select>
</mapper>
其中代码①处,加粗的命名空间(namespace)定义的正是接口TransactionDao的全限定名,这样就能将接口和这个映射文件捆绑到一起了。代码②处定义的id和TransactionDao的方法一致,这样就能够将SQL和方法捆绑到一起了。返回类型(resultType)的定义为“transaction”,与POJO的别名一致,也就是定义返回类型为POJO。
由于这里的支付方式是一个自定义的枚举类型,示意图在MyBatis中需要提供类型处理器(TypeHandler)进行处理。为此需要开发PaymentChannelHandler,如下图代码所示。
package com.spring.cloud.chapter14.type.handler;
/**** imports ****/
// 定义需要转换的Java类型
@MappedTypes(PaymentChannelEnum.class)
// 定义需要转换的Jdbc类型
@MappedJdbcTypes(JdbcType.INTEGER) // ①
public class PaymentChannelHandler
implements TypeHandler<PaymentChannelEnum> { // ②
@Override
public void setParameter(PreparedStatement ps, int idx,
PaymentChannelEnum pc, JdbcType jdbcType) throws SQLException {
ps.setInt(idx, pc.getId());
}
@Override
public PaymentChannelEnum getResult(ResultSet rs, String name)
throws SQLException {
int id = rs.getInt(name);
return PaymentChannelEnum.getById(id);
}
@Override
public PaymentChannelEnum getResult(
ResultSet rs, int idx) throws SQLException {
int id = rs.getInt(idx);
return PaymentChannelEnum.getById(id);
}
@Override
public PaymentChannelEnum getResult(
CallableStatement cs, int idx) throws SQLException {
int id = cs.getInt(idx);
return PaymentChannelEnum.getById(id);
}
}
先看一下①处,@MappedTypes配置的是Java类型,@MappedJdbcTypes配置的是Jdbc类型,这样就告诉MyBatis,该类型转换器是转换PaymentChannelEnum枚举和Integer类型的。再看代码②处,该类实现了TypeHandler接口,这意味着需要实现其声明的4个转换方法(也就是PaymentChannelHandler的4个方法),这是MyBatis框架定义的内容。
有了以上代码之后,我们还需要对其进行配置,在application.yml文件中加入如下配置。
mybatis:
# 配置映射文件
mapper-locations: classpath:/mybatis/*.xml
# 配置类型处理器(TypeHandler)所在包
type-handlers-package: com.spring.cloud.chapter14.type.handler
# 配置POJO包,以便别名扫描
type-aliases-package: com.spring.cloud.chapter14.pojo
配置多数据源
我们首先在application.yml中配置多个数据源所需的属性,代码如下
jdbc:
# 数据源1
ds1:
id: '001'
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/sc_chapter14_1?serverTimezone=UTC
username: root
password: 123456
default: true
# 数据源2
ds2:
id: '002'
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/sc_chapter14_2?serverTimezone=UTC
username: root
password: 123456
# 数据源3
ds3:
id: '003'
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/sc_chapter14_3?serverTimezone=UTC
username: root
password: 123456
# 数据库连接池配置
pool:
# 最大空闲连接数
max-idle: 10
# 最大活动连接数
max-active: 50
# 最小空闲连接数
min-idle: 5
这样3个数据源和数据库连接池的属性就都配置好了,跟着就是利用这些来配置数据源。我们来修改类,如下图代码所示。
package com.spring.cloud.chapter14.main;
/** imports **/
@SpringBootApplication(scanBasePackages = "com.spring.cloud.chapter14.*")
@MapperScan( // 定义扫描MyBatis的映射接口 ①
basePackages = "com.spring.cloud.chapter14.*", // 扫描包
annotationClass = Mapper.class) // 限定扫描被@Mapper注解的接口
public class Chapter14Application {
// 环境上下文
@Autowired
private Environment env; // ②
// 数据源id列表
private List<String> keyList = new ArrayList<>();
// 获取数据库连接池配置
private Properties poolProps() { // ③
// 获取连接池参数
Properties props = new Properties();
props.setProperty("maxIdle", env.getProperty("jdbc.pool.max-idle"));
props.setProperty("maxTotal",
env.getProperty("jdbc.pool.max-active"));
props.setProperty("minIdle", env.getProperty("jdbc.pool.min-idle"));
return props;
}
// 初始化单个数据源
private DataSource initDataSource(Properties props, int idx)
throws Exception {
// 读入配置属性
String url = env.getProperty("jdbc.ds"+idx+".url");
String username = env.getProperty("jdbc.ds"+idx+".username");
String password = env.getProperty("jdbc.ds"+idx+".password");
String driverClassName
= env.getProperty("jdbc.ds"+idx+".driverClassName");
// 设置属性
props.setProperty("url", url);
props.setProperty("username", username);
props.setProperty("password", password);
props.setProperty("driverClassName", driverClassName);
// 使用事务方式
props.setProperty("defaultAutoCommit", "false");
// 创建数据源 ④
return BasicDataSourceFactory.createDataSource(props);
}
// 初始化多数据源
@Bean
public AbstractRoutingDataSource initMultiDataSources() throws Exception {
// 创建多数据源
AbstractRoutingDataSource ds = new AbstractRoutingDataSource() { // ⑤
@Override
protected Object determineCurrentLookupKey() {
// 获取线程副本中的变量值
Long id = DataSourcesContentHolder.getId(); // ⑥
// 求模算法
Long idx =id % keyList.size();
return keyList.get(idx.intValue());
}
};
// 获取连接池属性
Properties props = poolProps();
int count = 1;
Map<Object, Object> targetDs = new HashMap<>();
do {
// 获取id
String id = env.getProperty("jdbc.ds"+count+".id");
// 如果获取id失败则退出循环
if (StringUtils.isEmpty(id)) {
break;
}
DataSource dbcpDs = this.initDataSource(props, count);
// 设置默认数据库
if ("true".equals(env.getProperty("jdbc.ds"+count+".default"))) {
ds.setDefaultTargetDataSource(dbcpDs); // ⑦
}
// 放入Map中
targetDs.put(id, dbcpDs);
// 保存id
keyList.add(id);
count ++;
} while (true);
// 设置所有配置的数据源
ds.setTargetDataSources(targetDs);
return ds;
}
......
}
这段代码比较长,但是结构清晰,核心代码是initMultiDataSources方法,其他都是辅助方法。代码中的注释已经比较清晰了,所以这里只对难点进行讲解。代码①处是配置MyBatis映射,这里配置了扫描包,并且限定扫描的注解为@Mapper。代码②处是注入一个环境上下文对象,它由Spring IoC容器自动装配,通过它可以读入Spring的配置。initMultiDataSources方法是代码的核心内容,它会执行以下几步。
- 代码⑤处通过匿名类的方式创建了一个路由数据源(AbstractRoutingDataSource),并且实现了determineCurrentLookupKey方法
- 利用代码③处的poolProps读入连接池属性,用于将来创建数据源(DataSource)。
- 使用循环通过代码④处的initDataSource方法,为每一个配置的数据库单独创建一个数据源对象(DataSource)。
- 通过代码⑦处设置默认的数据源
- 将创建的数据源放到一个Map中,其中key为配置的id,这个id会保存到列表(keyList)中
- 最后将数据源的Map对象存放到路由数据源(AbstractRoutingDataSource)中,这样它就可以通过key进行选择了
- 注意,在创建路由数据源的代码中,代码⑥处使用了线程副本的变量,关于这点后文还会谈到
这样,我们就配置了一个路由数据源,具体按照怎么样的规则选择数据源,由determineCurrent LookupKey方法决定的。因此代码清单14-7中代码⑥处还需要进一步的探讨,下面我先给出DataSourcesContentHolder的代码,如下图代码所示。
package com.spring.cloud.chapter14.datasource;
public class DataSourcesContentHolder {
// 线程副本
private static final ThreadLocal<Long> contextHolder = new ThreadLocal<>();
// 设置id
public static void setId(Long id) {
contextHolder.set(id);
}
// 获取线程id
public static Long getId() {
return contextHolder.get();
}
}
这个类的setId方法是设置一个Long型的线程变量,getId方法是获取这个线程变量。然后再看下图中创建路由数据源的代码。
// 创建多数据源
AbstractRoutingDataSource ds = new AbstractRoutingDataSource() { // ⑤
@Override
protected Object determineCurrentLookupKey() {
// 获取线程副本中的变量值
Long id = DataSourcesContentHolder.getId(); // ⑦
// 求模算法
Long idx =id % keyList.size();
return keyList.get(idx.intValue());
}
};
显然,这段代码是通过获取这个Long型的线程变量对数据源个数进行求余的方法来确定数据源key的,然后再通过key来找到数据源。为了进行测试,我们在数据库执行如下SQL代码。
/** 6382023274934274%3=0 **/
INSERT INTO sc_chapter14_1.t_transaction
(id,user_id, product_id, payment_channel,
amout, quantity, discount, trans_date, note)
VALUES(6382023274934272, 6382023274934274, 5646218600394760,
2, 100.00, 1, 20.00, '2019-08-01 13:00:00', '购买产品1');
/** 6382023279128578%3=1 **/
INSERT INTO sc_chapter14_2.t_transaction
(id,user_id, product_id, payment_channel,
amout, quantity, discount, trans_date, note)
VALUES(6382023274934276, 6382023279128578, 5646218600394760,
1, 100.00, 1, 20.00, '2019-08-01 14:00:00', '购买产品1');
/** 5646218600394755%3=2 **/
INSERT INTO sc_chapter14_3.t_transaction
(id,user_id, product_id, payment_channel,
amout, quantity, discount, trans_date, note)
VALUES(5646218600394752, 5646218600394755, 5646218600394760,
3, 100.00, 1, 20.00, '2019-08-01 12:00:00', '购买产品1');
注意,这些SQL代码不是随便写的,主要的焦点是用户编号(user_id),在每一条SQL前面的注释中,我已经告知user_id%3的值,这是一个求余运算,用来确定数据应该放在哪个数据库实例下。做好了这些,我们就可以编写控制器来测试多数据源了,代码如下。
package com.spring.cloud.chapter14.controller;
/**** imports ****/
@RestController
public class TransactionController {
@Autowired
private TransactionDao transactionDao = null;
@GetMapping("/transactions/{userId}")
public List<Transaction> findTransaction(
@PathVariable("userId") Long userId) {
// 设置用户编号,这样就能够根据规则找到具体的数据库
DataSourcesContentHolder.setId(userId);
return transactionDao.findTranctions(userId);
}
}
注意加粗的代码,这样写是为了将用户编号设置为线程变量,便于路由数据源找到具体的数据库。服务启动后,只需要在浏览器中请求3个地址:
- http://localhost:1014/transactions/6382023274934274;
- http://localhost:1014/transactions/6382023279128578;
- http://localhost:1014/transactions/5646218600394755。
就可以验证开发的路由数据源是否成功了。但是这样由每一个方法写一次会有些麻烦,例如,某个用户已经登录了系统,就有必要在上下文中设置用户编号,用于选择数据库。为了处理这个问题,有些开发者使用Spring AOP的通知去设置线程变量的方法,但是这样比较麻烦,毕竟Spring AOP的写法也有些不太友好,更多的时候,我推荐使用Web容器的过滤器,如下图代码所示。
package com.spring.cloud.chapter14.filter;
/**** imports ****/
@Component
// 配置拦截器名称和拦截路径
@WebFilter(urlPatterns = "/*",filterName = "userIdFilter")
public class UserIdFilter implements Filter {
private static final String SESSION_USER_ID = "session_user_id";
private static final String HEADER_USER_ID = "header_user_id";
// 拦截逻辑
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
HttpServletRequest hreq = (HttpServletRequest) request;
// 尝试从Session中获取userId
Long userId = (Long)hreq.getSession().getAttribute(SESSION_USER_ID);
// 如果为空,则尝试从请求头获取userId
if (userId != null) {
String headerId = hreq.getHeader(HEADER_USER_ID);
if (!StringUtils.isEmpty(headerId)) {
userId = Long.parseLong(headerId);
}
}
if (userId != null) { // 如果存在userId则设置线程变量
DataSourcesContentHolder.setId(userId);
}
chain.doFilter(request, response);
}
}
在这个拦截器中,尝试从Session和HTTP请求头中获取用户编号(userId),如果能够获取得到,就设置线程变量,这样后续的方法就不必再设置了。
在选择数据库的时候,本文选择的是求余的方法,这当然是一种算法,但这种算法也有许多的弊端。此外,还有其他选择数据库的算法,它们都有各自的优点,这便是下一节要讨论的分片(sharding)算法。
分片算法
无论是分表、分库和分区,都是将一张表的记录分隔到不同的区域存储,每个区域如同一个片区,为了让这些分散的片区能够整合成为一个整体,就需要对应的分片算法了。常见的分片算法也有多种,大体分为范围分片、哈希(Hash)分片和热点分片。哈希分片又分为求余分片和一致性哈希算法。因为范围分片的算法比较简单,并且当前使用得不多了。
一般来说,基于数据的特性,企业会按用户数据进行区分,并且主要以用户编号为区分依据。这里有一个最基本的原则,就是尽量把同一个用户的数据存储到同一个分片中,因为这些数据往往有一定的关系,如果可以在同一个分片访问,就可以减少跨分片访问和由此带来的资源消耗,从而提高访问性能。拿我们的例子来说,如果根据交易记录ID进行分片,那么一个用户的交易记录就有可能同时有sc_chapter14_1、sc_chapter14_2和sc_chapter14_3这3个库中,如果想组织一个整体数据展示给用户看,就需要访问3个数据库,这无疑会给系统开发带来很大的困难,同时性能也不会好。对于那些与用户无关的数据,则需要根据其自身业务进行分析了。例如,产品微服务系统,可能就需要根据产品编号进行分片了,因为产品本身可能有许多关联业务,所以拿产品编号分片就显得更为合理一些。
为了方便,下文就使用用户编号(userId)来讨论。在13章中我们谈到了SnowFlake算法的发号机制,这里假设我们采用这个算法来生成Long类型的userId,那么我们该如何使用userId来决定将数据存储到哪个分片呢?这便是分片算法要解决的问题。
哈希分片之求余算法
常见的哈希算法有两种,一种是求余算法,另外一种是一致性哈希算法。相对来说,求余算法很简单,例如,在14.2节中我们就已经使用了,例子中有3个库,即sc_chapter14_1、sc_chapter14_2和sc_chapter14_3。我们只需要使用userId对3进行求余,就知道要存入哪个数据库了,这个算法十分简单易行,如下图代码所示。
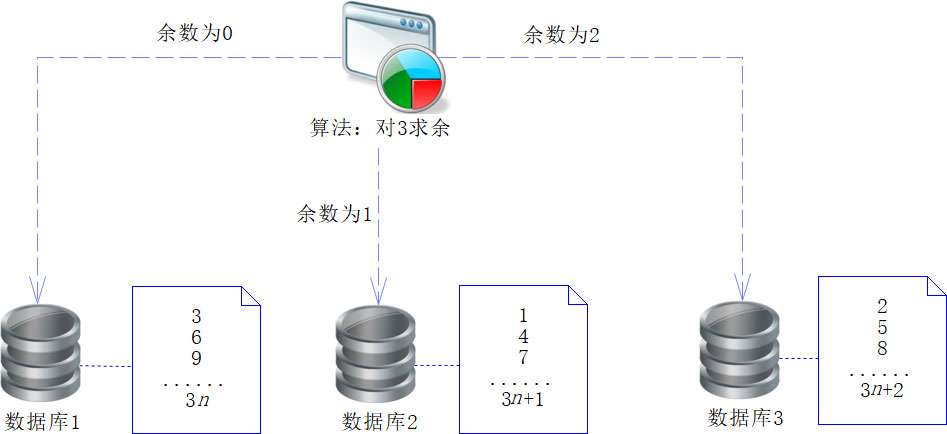
有些企业会采用这个模型,因为它简单方便,性能也很好。但是对于数据量快速增长的企业来说,采用这个模型就会有很多问题,其中最主要的就是伸缩性问题。例如,因为数据量不断膨胀,所以3个库已经不够用了,要增加1个库,从3个库变为4个库,就需要通过使用userId对4求余来决定将数据存放到哪个库。当然,这对新的用户数据没有什么影响,但是旧的用户数据就必须迁徙了。然而,所有数据库的数据都做迁徙,无疑需要大量的时间和代价,成本也较高。对于那些已经部署了数百个数据库的企业,当出现业务增长缓慢、出现资源浪费、需要为了节省成本而减少数据库的时候,也要迁徙所有的数据才能重新部署。所以这样的算法不适合那些频繁增加和减少节点的企业,为了满足业务伸缩性较大的企业的需求,有软件开发者提出了新的算法——著名的一致性哈希算法。
一致性哈希算法
一致性哈希算法,也称为一致性哈希算法,它是1997年麻省理工学院提出的一种算法。它首先假设一个圆由232个点构成,如下图代码所示。
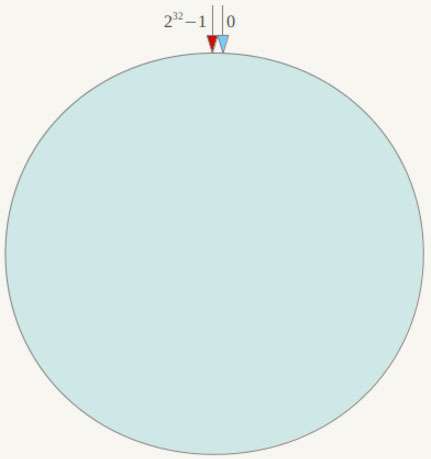
对于这个圆,我们也称为哈希环,它由232个节点组成,数值的取值范围为区间[0, 232 −1]。我们可以根据数据库编号或者其他标识性的属性求其哈希值(hash code),然后该值就会对应到这个哈希环上的某一点。
我们有4个库,依次编号为Node A、Node B、Node C和NodeD,它们都是我们数据库的节点。根据编号求出哈希值,就可以放到图14-5的节点中了,如下图代码所示。

为了进行说明,这里需要进行一些假设。
- 假设Node A、Node B、Node C和NodeD这4个节点的哈希值为Hash A、Hash B、Hash C和Hash D,根据图14-6就可以得到以下5个区间:[0, Hash A]、[Hash A,Hash B]、[Hash B, Hash C]、[Hash C, Hash D]和[Hash D, 232 −1)。
- 假设对userId也求哈希值,记为n,而n必然落入Node A、Node B、Node C和NodeD这4个节点所产生的5个区间之中。
在一致性哈希算法中,对于n,采用顺时针方向找到下一个数据库节点,用来存放该数据。

